Deploying AI Object Detection, Target Tracking and Computational Imaging Algorithms on Embedded Processors

The rapid advances in AI (deep learning) techniques for digital vision-based perception and computational imaging for image quality gains has converged with the rapid advances in mobile processors and device support that brings very large compute power to the edge. This convergence is creating opportunities for electro optical systems to become intelligent at the edge and eliminate issues with latency, compression artifacts, datalink bandwidth, thermal management, and system complexity. We describe the state of the art in embedded processors and the integration of Teledyne FLIR’s Prism™ thermal and multispectral image signal processing and object detector and tracking libraries on to today’s most widely deployed embedded platforms.
TABLE OF CONTENTS
- Introduction
- Advances in Lightweight Models and Mobile Processors
- Designing a Neural Network for Embedded Platforms - Introducing Pelee
- Optimization
- The Rapid Development Power of Mobile Processors
- Frameworks
- Video Processing Pipeline
- ISP Functions
- Conclusions
1. Introduction
At the 2012 ImageNet Large Scale Visual Recognition Challenge (ILSVRC), the emergence of AlexNet, a convolutional neural network (CNN) architecture, marked a significant leap forward in the field of artificial intelligence. This fundamentally changed the challenges of object detection from relying on handcrafted feature extraction to generating large training datasets and using those to train increasingly sophisticated neural networks. The success of AlexNet highlighted the scalability and generalization abilities of deep neural networks. As is often the case in early technology development, little concern was raised over the computing power needed to train and run CNNs.
This lack of concern limited how this new technology could be used in vision-based systems, especially video-centric applications where the need for real-time object classification, metadata generation, and alerts is critical. At the same time, an arms race was being waged in the mobile phone industry around camera performance, which led to the rapid development of highly advanced image signal processors (ISPs) that enabled ever-improving camera performance using algorithms and what is now referred to as computational imaging (CI). Recent advances in large language models, or LLMs, are only adding to the market demand for more power in mobile processors.
Today’s class of processors features very powerful architectures with multiple CPU, GPU, and DSP cores in addition to dedicated ISP compute blocks. In addition, the open-source community has contributed many of the building blocks used to create perception systems, including networks like YOLO, platform-agnostic DNN file formats like ONNX, development frameworks including PyTorch and Tensor FLOW, and open datasets for network training and model validation. Hardware suppliers provide development tools that accelerate the deployment of perception software including tools to convert ONNX format models to the specific compute accelerators supported by their processors.
Teledyne FLIR is focused on integrating perception and computational imaging or image signal processing to highly size, weight, and power (SWaP) optimized processors for a wide range of applications. Leveraging new silicon designs fabricated on the most advanced nodes enables system developers to increase battery life and simplify system thermal management.
2. Advances in Lightweight Models
and Mobile Processors
Once the impact of deep learning on computer vision was recognized, work commenced on developing neural networks and models that could run at the edge on low-cost mobile processors, enabling object detection for video applications including vehicle autonomy, advanced driver assistance systems (ADAS), security, and automatic target recognition. Other software packages incorporated into vision-based products include SLAM (Simultaneous Localization and Mapping), collision avoidance, and object tracking. These computationally demanding features, when compiled for a specific hardware (HW) architecture, will be mapped to various subsystems of target system on chip (SoC), such as GPU or CPU. Managing all these computational tasks across the newest processor architectures is a significant engineering challenge, but enables significant power savings over the past few SoC product lifecycles. In just a few years, SoCs have gone from a 10 nm to a 4 nm foundry node, resulting in dramatically lower dynamic power.
Table 1 - Generation of Embedded Processors
Embedded Processors |
Foundry Node |
Trillion Operations Per Second |
||
TOPS |
TOPS/watt |
$/TOPs |
||
|
NVIDIA Orin Nano 4 GB 2023 |
8nm |
20 |
2 |
$10 |
|
Qualcomm 845 (2017) |
10nm |
3 |
1 |
$50 |
|
Qualcomm QRB-5165 (2021) |
7nm |
15 |
3 |
$23 |
|
Qualcomm QCS8550 (2024) |
4nm |
48 |
10 |
$8 |
Image signal processing and AI object detection algorithms are computationally expensive. For example, Teledyne FLIR’s advanced denoising and super-resolution algorithms perform up to 100,000 operations per pixel per second (approximately 2 trillion operations per second for a 640x512 resolution input at 60 frames per second (fps)) and run on a GPU core. Running large object detection models also consumes a lot of processing power and runs on the DSP subsystem (Qualcomm®) or GPU (NVIDIA®).
There are many variables to consider when developing and deploying an object detector, including the processor architecture, the desired accuracy, acceptable latency or frame rate, and the power/thermal budget. In response to demands to run object detectors on embedded processors, several low-power neural networks were developed, including YOLO (You Only Look Once) by Joseph Redmon from the University of Washington in 2015 and MobileNet by Google in 2017.
YOLO revolutionized object detection with its single-pass approach. Unlike RCNN networks involving multiple stages such as region proposals followed by classification, YOLO accomplishes detection and localization in a single forward pass of the network. By dividing an input image into a grid and predicting multiple bounding boxes and class probabilities simultaneously for each grid cell, the YOLO algorithm offers both speed and accuracy. One-stage detectors use a single feed-forward convolutional network to directly predict object classes and locations. YOLO frames object detection as a regression problem that spatially separates bounding boxes and associates class probabilities. In this way, both object classes and locations can be directly predicted by a convolutional network. SSD (single shot detector) improves YOLO in several aspects, including using multi-scales of features for prediction and using default boxes and aspect ratios for adjusting varying object shapes. While two-stage approaches generally produce higher accuracy, the one-stage approach generally operates at a higher efficiency.[i]
3. Designing a Neural Network for Embedded Platforms - Introducing Pelee™
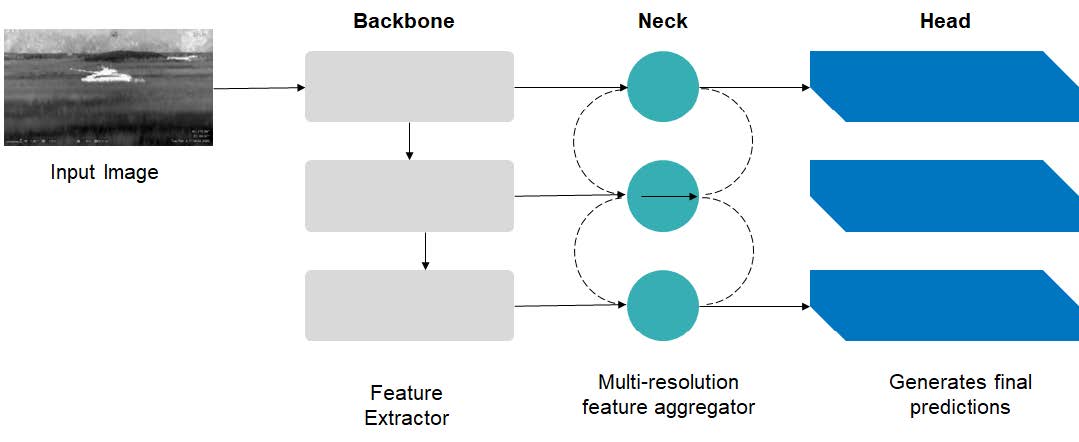
Figure 1 - Architecture of Object Detector
Teledyne FLIR extended the single-pass approach with the development of its Pelee network (patent pending).[i] CNNs are comprised of three main blocks: the feature extractor or backbone; a feature aggregator or neck; and the head or object detector. Pelee features a new backbone design that is built with a dense connectivity pattern to encourage feature reuse, and a two-way dense layer to get different scales of receptive fields. Pelee incorporates a new feature fusion block (FFB) based on the Path Aggregation Feature Pyramid Network (PANet). Designed with small target detection in mind, the new FFB adopts a late fusion strategy, which aims to ensure that each feature map of the output retains the detailed information learned from the shallow layers and acquires high-level semantic features.
Framework |
backbone |
computational cost (flops) |
||
TOPS |
TOPS/watt |
$/TOPs |
||
|
SSD |
VGG |
31.9 |
34.2 |
93.3% |
|
RefineDet |
VGG |
31.9 |
37.38 |
85.3% |
|
YOLOv3 |
DarkNet 53 |
14.51 |
19.54 |
74.2% |
|
RetinaNet |
ResNet101 |
15.48 |
34.51 |
53.4% |
The backbone network directly affects the memory, speed, and performance of the object detector. In SSD CNN, over 90% of the computation cost is consumed by the backbone network. Teledyne FLIR’s CNN incorporates a new backbone design that avoids using a squeeze and excitation block, carefully selects activation functions according to the hardware, and adjusts the network’s width and depth according to the hardware.
Figure 2 - Pelee Backbone Based Model Performance

Figure 3 – Pelee versus YOLO Networks Performance Comparison
4. Optimization
Quantization
Quantization is the compression of floating-point values in neural network parameters to improve model latency when running inference without losing performance. Model training is performed using 32-bit floating point data and training is done on powerful GPU based computers designed for this task. Inference on embedded processors can be performed using FP16, FP8, INT8, or INT4 bit depths.
Teledyne FLIR uses INT8 to reduce memory footprint, compute time, and energy consumption, as many in the field have found, this is a good compromise between precision and speed. Qualcomm’s QCS8550 also supports FP16, however this will reduce the maximum frame rate and result in a longer duty cycle of the HVX core along with higher power consumption. Gaining back compute resources gives developers the flexibility to add more capabilities, including real-time inference on two or more camera feeds.
Pruning
Pruning is a method used to reduce redundant data in the neural network by determining the importance of each unit and removing unimportant parts. After training, many of the network neurons have a weight value of 0, so these neurons can be eliminated through a secondary network training process after quantization. Current pruning methods include weight pruning, channel pruning, and neuron pruning, each with its advantages and disadvantages.
The criteria for determining the importance of the unit can impact the accuracy. The use of constraint learning methods can improve it, although the implementation is complex. The random search method of pruning is simple to implement, but the network model’s performance is limited compared to other methods that improve it. Therefore, each method needs to be selected in conjunction with the actual application scenario. There is no single method that can synthesize the complexity and model compression efficiency.[i]
Thermal Management
For many product categories, including drones and weapon sights, power consumption is a critical design constraint. High consumption limits the operating time, adds support logistics challenges, and adds complexity and costs for thermal management. For some battery-operated devices, the choice is to use an FPGA or an ASIC processor to keep power to an absolute minimum, but third-party analytics and ISP software are not available, as these libraries are typically compiled to run on ARM processors and other cores using open-source components and frameworks like Open CV. While this is not the case for the most power-constrained products, the power demands of new generation embedded processors fabricated on 4 nm to7 nm nodes offer systems designers many options for adding high-value capabilities to products.
For a system running multiple cameras and running multiple feature routines like an object detector, target tracker, and local contrast enhancement, the developer will reach the upper limit of the processor’s throughput and generate a lot of heat. To help manage this, software developers can build in configuration parameters that can be set or adjusted dynamically. For example, for many applications it is not necessary to do inference at frame rate. By reducing the inference output to 10 fps or less, the power profile of the entire software stack may be managed to fit the power budget.
5. The Rapid Development Power
of Mobile Processors
Running CNN models and CI algorithms is extremely computationally demanding. Until recently, embedded processors did not have the power to meet AI and CI workloads. AI requires massive parallelism of multiply-accumulate functions. Traditional GPUs were able to do parallelism in a similar way for graphics, so they were reused for AI applicaQualtions, particularly for model training. As a result, NVIDIA has established itself as the dominant player in model training.
Today’s mobile processors are amazing feats of engineering. For example, Qualcomm’s QCS8550 SoC is a 4-nm design that features eight CPU cores, two neural co-processors, a graphics processing unit (GPU), digital signal processing (DSP), and a dedicated ISP. The integrated ISP features compute resources for motion-compensated noise reduction, white balance, color processing, automatic gain control, focus, and many other camera functions. This class of chip costs over $600 million to develop and requires billions of dollars in foundry investments.
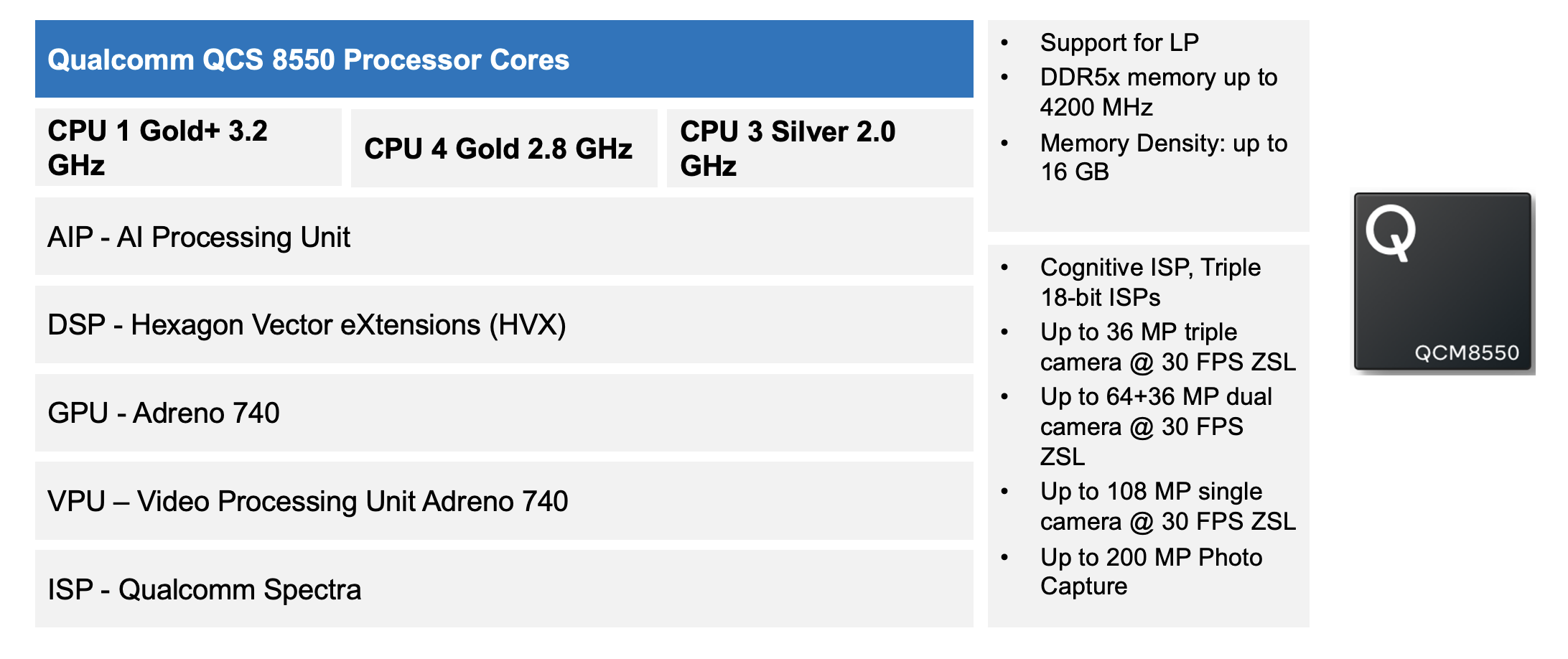
Figure 5 - QCS 8550 Processor Cores
Teledyne FLIR wanted to create a platform that our customers could build their products around — one that would allow creation of highly-integrated software stacks and minimize cost, latencies, and power by using a single processor. This has been the goal over several platform generations, including the selection of the Intel® Myriad™ processor for Teledyne FLIR Boson® thermal infrared (IR) camera module. The Myriad chip architecture could not meet the heavy compute needs for computational imaging or CNN-based object detectors. With the introduction of the NVIDIA Xavier and the Qualcomm RB5 QCS5165, it became practical to run multiple software stacks distributed across specific processor cores.
System on Chip (SoC) Overview
Today’s embedded processors leverage the latest in foundry nodes, enabling multi-core designs with unified memory. Processor suppliers offer very comprehensive development support, and developers can deploy their code on these multicore processors to maximize performance while meeting power and thermal budgets.
CPU
The core functionality of the CPU is to fetch instructions from random access memory, or RAM, and then decode and execute the instructions. CPUs are generalist processors designed to execute routines that handle sequential workloads. Many CPUs have built-in vector processors to speed up some operations (ex. NEON on ARM-based CPUs). Several of Teledyne FLIR’s digital product capabilities run on CPU cores, including Prism ISP correlation video tracker and electronic video stabilization. Given the large number of CPU cores available on current generation SoCs, developers have tremendous flexibility to optimize performance and power. CPUs are not a good fit for tasks requiring large numbers of mathematical operations per pixel. CPUs have throughput limitations and consume relatively high power per operation.
GPU
AI and CI workloads are massive, demanding a significant amount of bandwidth and processing power. Processor designers have created powerful chip architectures integrating memory, security, and real-time data connectivity. Traditional CPUs typically lack the processing performance needed but are ideal for performing sequential tasks. GPUs can handle the parallelism of AI’s multiply-accumulate functions and can be applied to AI applications. In fact, GPUs can serve as AI accelerators, enhancing performance for neural networks and similar workloads. GPUs can have thousands of compute cores and are used for many parallel processing tasks. GPUs are especially useful for training models. However, GPUs consume significant power and have higher on-chip memory requirements. For this reason, modern mobile processors use dedicated AI co-processors using digital signal processors (DSPs) for running inference at the edge.
DSP
DSPs are specialized and power-efficient SoC subsystems optimized to execute mathematical operations. They utilize wide instruction words to help maximize processing per clock cycle. However, they are not as easy to program, requiring familiarity with the features of the DSP hardware, programming environment, and optimization of DSP software to achieve the best performance. The Qualcomm Hexagon™ Tensor Processor HTP is an AI accelerator that is suited for running computationally intensive AI workloads. To get improved performance and run an AI model on HTP, a model must be quantized to one of the supported precisions: INT4, INT8, INT16, or FP16.
ISP
Because digital photography is the front line of the competitive battle in the mobile handset industry, mobile processor suppliers incorporate dedicated silicon IP blocks to perform image enhancement functions including noise reduction, lens distortion correction, white balancing, auto exposure, auto-focus, de-mosaicing, and image compression. At the system level, ISP tuning is typically needed to optimize the parameters and various filters to a specific image sensor and lens. ISP fine-tuning is an industry unto itself. Many SoC suppliers offer ISP libraries for popular image sensors, potentially saving systems developers a significant investment.
There is little justification for mobile processor suppliers to design and fabricate a thermal camera ISP. Still, the benefits of image signal processing are valuable, so Teledyne FLIR has developed a comprehensive set of ISP features including 16 to 8-bit tone mapping (automatic gain control), spatiotemporal de-noising, super-resolution, turbulence mitigation, and electronic image stabilization. Most of these algorithms run on GPUs given the significant processing demands.
Memory
Given the high data rates in digital video streams and that data is common to potentially multiple reads, large memory capacity and memory bandwidth are critical to achieving efficient signal processing. Through a combination of increased clock speeds and higher memory bandwidth, Teledyne FLIR’s largest existing AI model (768x768 pixel input resolution) is executed in 6 ms on the Qualcomm QCS8550 versus 33 ms on the QRB5165. This represents a more than 5X increase in inference speed and gives a safe margin for achieving inference at frame rate for our next generation of SXGA (1280x1024) resolution cameras.
6. Frameworks
AI frameworks are foundational building blocks that shape how we create, implement, and deploy intelligent systems. These frameworks, equipped with libraries and pre-built functions, enable developers to craft sophisticated AI algorithms without having to design every function from scratch. They streamline the development process, ensuring consistency across various projects and enabling the integration of AI functionalities into diverse platforms and applications.
PyTorch is centered around flexibility and user-friendliness. Its dynamic computation graph (eager execution) allows developers to change the behavior of their models on the fly and use Python control flow operations. This dynamism is particularly well suited for complex, iterative model architectures where changes are frequently made.
On the other hand, TensorFlow uses a static computation graph which requires the definition of the entire model architecture upfront, before any actual computation occurs. This approach, while less flexible than PyTorch, allows for more straightforward optimization of the models, potentially leading to better performance at scale. TensorFlow has a slight edge in optimization and resource management for large-scale projects, while PyTorch provides flexibility that can be advantageous in rapidly changing and experimental scenarios.[i]
7. Video Processing Pipeline
Teledyne FLIR developed Prism ISP, a collection of image processing software libraries for thermal images that include local contrast enhancement (LCE), spatial and temporal noise reduction, electronic image stabilization, turbulence mitigation, super-resolution, and several video fusion techniques. This maximizes operational flexibility and accounts for ever-increasing resolution while minimizing power requirements and cost. Thermal camera modules from Teledyne FLIR do not include integrated processors to run Prism ISP. With the availability of the latest mobile processors, it is now practical to add an accessory electronics module with the power to run algorithms at the required video frame rates while meeting acceptable power demands.

Figure 6 - Prism Video Processing Pipeline
Across the many use cases, thermal imaging is used to visualize objects at meters distances for inspection and firefighting to multiple kilometers in intelligence, surveillance, and reconnaissance (ISR) and from aerial, tower-based, and ground-level perspectives. The combination of range, perspective, and day, night, and weather-based environmental conditions create real-world imaging challenges that can be mitigated with Prism ISP algorithm functions.
8. ISP Functions
Turbulence Mitigation

Figure 7 - Turbulence Mitigation
Atmospheric turbulence refers to the irregular and chaotic motion of fluid or air characterized by velocity, pressure, and density fluctuations. Turbulence affects photon transmission because the solar gain of the surface causes the atmosphere to mix. It churns the air and causes water vapor, smoke, and other substances to alter the refraction of the infrared signal. Advanced techniques remove the distortion effects while maintaining good temporal image element quality, meaning objects in motion are not transformed into indistinguishable blobs or streaks. This is critical when detecting targets, including people and vehicles, using AI.
The primary goals of turbulence mitigation algorithms are to enhance signal quality, reduce noise, and restore clarity and stability in turbulent conditions. The Prism ISP algorithm employs various mathematical and signal-processing techniques to analyze and process the data affected by turbulence.
1. Data Acquisition:The first step is to acquire the data affected by turbulence. This is presented in the form of image frames.
2. Preprocessing: The acquired data is pre-processed to remove noise or artifacts that are not directly related to turbulence. This involves filtering, noise reduction, and calibration techniques to improve the signal quality.
3. Turbulence Estimation: It is essential to estimate the turbulence characteristics present in the data. This involves analyzing the statistical properties of the fluctuations and identifying relevant parameters such as turbulence intensity, correlation length, and time scales.
4. Deconvolution or Reconstruction: Deconvolution techniques attempt to reverse the blurring effects caused by turbulence. Deconvolution algorithms often utilize mathematical models of turbulence or empirical knowledge to restore the original signal.
5. Adaptive Filtering: Turbulence conditions can vary over time and space, so many turbulence mitigation algorithms employ adaptive filtering techniques. These methods dynamically adjust the filtering parameters based on estimated turbulence parameters to optimize the trade-off between noise reduction and the preservation of essential signal features.
6. Post Processing: After the turbulence mitigation steps, additional post-processing may be performed to enhance the quality further and reduce artifacts in the final output. Depending on the specific application, this may involve techniques such as denoising, sharpening, contrast enhancement, or feature extraction.
Super Resolution

Figure 8 – Super Resolution
Multi-frame super-resolution is a powerful technique that aims to reconstruct a high-resolution image from one or more low-resolution images. The optical resolution of a system is limited by the diffraction limit set by the system aperture and the sampling resolution of the detector. A small aperture and a low-resolution sensor will result in a cheaper and smaller system that will result in poor-quality images with highly aliased and/or blurred edges. This is especially true when long-range targets are captured using a long focal length optic that scales the effects of diffraction when combined with a finite aperture size. By employing sophisticated algorithms, super-resolution reconstructs high-resolution images using data from the degraded inputs. While traditional methods have predominantly focused on exploiting the inherent spatial correlations within low-resolution images, recent advancements have demonstrated the efficacy of leveraging aliasing techniques to achieve superior results.
Image Stabilization

Figure 9 - Typical Applications for Electronic Stabilization
Cameras are often mounted on moving platforms such as ground vehicles, marine craft, aircraft, drones, or towers. Platform motion transfers directly onto the video image, which can lead to viewer fatigue and poor image quality, impacting situational awareness and evidence fidelity. Electronic stabilization eliminates most motion-induced image distortion, particularly when imaging through a narrow field of view zoom optic used for long-range imaging.
MSX - Multi-Spectral Dynamic Imaging

Figure 10 - FLIR MSX Embosses the Visible Edges on Thermal Images in Real Time
There are many different approaches to image fusion or blending thermal and visible imagery into a single fused video stream. The objective is to bring out each spectrum's unique and valuable information while not requiring the transmission of two or more streams for downstream human operators or systems to have to analyze. This can be complex in practice due to the need for perfect image registration (alignment) of two or more channels and issues due to the different integration times for each sensor.
Teledyne FLIR patented a unique technology called MSX (multi spectral fusion). Unlike image blending (mixing a visible light and thermal image), MSX does not remove thermal details or decrease thermal transparency. It applies a high-frequency filter to extract sharp visible details like symbology, including outlines, words, numbers, and other high-contrast edge details, and overlay them on the thermal image. This helps give the image definition and has proven to be a beneficial technology in fields like prediction maintenance, security, and aerial ISR applications.
AGC – Automatic Gain Control

Figure 11 - Local Contrast Enhancement (Boson® 640 source video)
In the context of images, contrast refers to the difference in intensity between the brightest and darkest regions. It plays a crucial role in defining the overall visual impact of an image. Local contrast enhancement, also known as local contrast stretching, operates on the principle of expanding the dynamic range of contrast within specific regions of an image rather than globally altering the entire image's contrast.
Local contrast enhancement brings out intricate details, enhances textures, and accentuates features. Converting raw 16-bit monochrome sensor data into the 8-bit color depth we see on displays relies on algorithms to map the extensive distribution of pixel values into 1 of 256 shades of color or gray. Because the distribution of pixel values in an image is rarely linear, maximizing contrast is highly complex and dynamic from scenario to scenario. Unlike global contrast enhancement, which adjusts the contrast across the entire image uniformly, local contrast enhancement focuses on preserving local details and fine textures. It targets smaller regions within the image and amplifies the contrast within those regions while maintaining the relative contrast relationships between neighboring regions.
9. Conclusions
Since the publication of AlexNet in 2012, there have been remarkable advances in deep learning. The early innovations in neural networks advanced more rapidly than hardware, as product life cycles for silicon devices are much longer. The convergence in processing power and efficient neural networks make it practical to add very powerful image signal processing and sophisticated and highly precise perception software into products while enabling these devices to run efficiently. The enormous economic resources put to work in the mobile processor industry and the efforts of the open-source community will drive continued dramatic improvements in speed, accuracy, and power in smart devices.
Across industries including automotive, security, and defense, the proliferation of edge intelligence will be remarkable and provocative. The next frontier in intelligent systems will be around data as the industry continues to iterate perception systems to ever-higher degrees of accuracy and general intelligence.
[i] https://patentimages.storage.googleapis.com/f5/e3/05/021253fa9a6921/US20220019843A1.pdf
[ii] https://patents.google.com/patent/US20220019843A1/en?oq=17%2f374909
[iii] A Review of Artificial Intelligence in Embedded Systems https://doi.org/10.3390/mi14050897
Related Articles
-
 Press Release
Press Release
New Qualcomm-Built Advanced Video Processor by Teledyne FLIR Powers AI at the Edge
Read the story -
 Fundamentals
Fundamentals
Simplify MWIR Development with Neutrino Featuring InVeo Electronics
Learn more -
 Fundamentals
Fundamentals
Comparing Sensitivity of Thermal Imaging Camera Modules
Learn more